روش موازی موثر برای داده کاوی ژنتیکی - فازی
- عنوان لاتین مقاله: An effective parallel approach for genetic-fuzzy data mining
- عنوان فارسی مقاله: روش موازی اثربخش برای داده کاوی ژنتیکی - فازی
- دسته: فناوری اطلاعات IT - داده کاوی
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 23
- جهت دانلود رایگان نسخه انگلیسی این مقاله اینجا کلیک نمایید
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
مهم ترین کاربرد داده کاوی در تلاش هایی است که برای استنتاج قواعد وابستگی از داده های تراکنشی صورت می گیرد. در گذشته، از مفاهیم منطق فازی و الگوریتم های ژنتیکی برای کشف قواعد وابستگی فازی سودمند و توابع عضویت مناسب از مقادیر کمی استفاده می کردیم. با وجود این، ارزیابی مقادیر برازش نسبتاً زمان بر بود. به دلیل افزایش های شگرف در قدرت محاسباتی قابل دسترسی و کاهش همزمان در هزینه های محاسباتی در طول یک دهۀ گذشته، یادگیری یا داده کاوی با به کارگیری تکنیک های پردازشی موازی به عنوان روشی امکان پذیر برای غلبه بر مسئلۀ یادگیری کند شناخته شده است. بنابراین، در این مقاله الگوریتم داده کاوی موازی فازی – ژنتیکی را بر اساس معماری ارباب - برده ارائه کرده ایم تا قواعد وابستگی و توابع عضویت را از تراکنش های کمی استخراج کنیم. پردازندۀ master مانند الگوریتم ژنتیک از جمعیت یگانه ای استفاده می کند، و وظایف ارزیابی برازش را بین پردازنده های slave توزیع می کند. اجرای الگوریتم پیشنهاد شده در معماری ارباب – برده بسیار طبیعی و کارآمد است. پیچیدگی های زمانی برای الگوریتم های داده کاوی ژنتیکی – فازی موازی نیز مورد تحلیل قرار گرفته است. نتایج این تحلیل تأثیر قابل توجه الگوریتم پیشنهاد شده را نشان داده است. هنگامی که تعداد نسل ها زیاد باشد، افزایش سرعت الگوریتم ممکن است نسبتاً خطی باشد. نتایج تجربی تیز این نکته را تأیید می کنند. لذا به کارگیری معماری ارباب – برده برای افزایش سرعت الگوریتم داده کاوی ژنتیکی – فازی روشی امکان پذیر برای غلبه بر مشکل ارزیابی برازش کم سرعت الگوریتم اصلی است.
کلمات کلیدی: داده کاوی، مجموعه های فازی، الگوریتم ژنتیک، پردازش موازی، قاعده اتحادیه
مقدمه
با پیشرفت روزافزون فن آوری اطلاعات (IT) ، قابلیت ذخیره سازی و مدیریت داده ها در پایگاه های داده اهمیت بیشتری پیدا می کند. به رغم اینکه گسترش IT پردازش داده ها را تسهیل و تقاضا برای رسانه های ذخیره سازی را برآورده می سازد، استخراج اطلاعات تلویحی قابل دسترسی به منظور کمک به تصمیم گیری مسئله ای جدید و چالش برانگیز است. از این رو، تلاش های زیادی معوف به طراحی مکانیسم های کارآمد برای کاوش اطلاعات و دانش از پایگاه داده های بزرگ شده است. در نتیجه، داده کاوی، که نخستین بار توسط آگراول، ایمیلنسکی و سوامی (1993) ارائه شد، به زمینۀ مطالعاتی مهمی در مباحث پایگاه داده ای و هوش مصنوعی مبدل شده است.
- فرمت: zip
- حجم: 1.19 مگابایت
- شماره ثبت: 411

الگوریتم امتیازدهی کارآمد برای مدل ترکیبی گاوس
- عنوان لاتین مقاله: An Efficient Routing Algorithm to Support Multiple Concurrent Applications in Networks-on-Chip
- عنوان فارسی مقاله: الگوریتم امتیازدهی کارآمد برای مدل ترکیبی گاوس بر مبنای شناسایی گوینده
- دسته: مهندسی صنایع
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 9
- لینک دریافت رایگان نسخه انگلیسی مقاله: دانلود
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
این مقاله الگوریتم جدیدی را در ارتباط با کاهش پیچیدگی های محاسباتی در تشخیص صدای افراد بر مبنای چارچوب مدل گویش ترکیبی گاوس ارائه می کند. در ارتباط با موارد کاربردی که در آن ها سلسله مراتب مشاهدات کلی مد نظر قرار می گیرد، به توضیح این مطلب می پردازیم که بررسی سریع مدل های احتمالی تشخیص صدا از طریق تنظیم توالی زمانی بردارهای مشاهداتی مورد استفاده برای بروزرسانی احتمالات جمع آوری شده مربوط به هر مدل گوینده، حاصل می گردد. رویکرد کلی در استراتژی جستجوی مقدماتی ادغام می شود، و نشان داده شده است که باعث کاهش زمان برای تعیین هویت گوینده از طریق فاکتورهای 140 بر روی روش های جستجوی استاندارد کلی و فاکتور شش با استفاده از روش جستجوی مقدماتی شده است. که گویندگان را از مجموع 138 گوینده دیگر تشخیص می دهد.
مقدمه
توانایی تشخیص صدای هر فرد اخیرا در تحقیقات پیشین مورد توجه قرار گرفته است. کاربرد های شناسایی و تشخیص صدای هر فرد در ارتباط با تماس های تلفنی، امنیت کامپیوتری و همچنین دسترسی به اسناد مهم بر روی اینترنت می باشد. استفاده از مدل ترکیبی گاوس برای تعیین هویت گویندگان عملکردهای قابل مقایسه ای را در ارتباط با تکنیک های موجود دیگر ایجاد کرده است. برای نمونه، میزان خطا در ارتباط با 138 گوینده به میزان 0.7% کاهش نشان داده است. به هر حال با افزایش اندازه جمعیت و ابزارهای آزمایشی، هزینه محاسباتی اجرای این بررسی ها به طور اساسی افزایش داشته است. این مقاله مسئله کاهش پیچیدگی های محاسباتی شناسایی هویت گوینده را با استفاده از جستجوی مقدماتی همراه با تنظیملت جدید سلسله مراتب مشاهدات مد نظر قرار می دهد.
- فرمت: zip
- حجم: 0.62 مگابایت
- شماره ثبت: 411
خلاقیت که دستورالعمل ها (علامت ها) را می شکافد

دسته: مدیریت
حجم فایل: 499 کیلوبایت
تعداد صفحه: 7
خلاقیت که دستورالعمل ها (علامت ها) را می شکافد
یک قرن از انقلاب مربوط به تبلیغات اینترنتی می گذرد، آیا این برای همه چیز در این زمینه خلاقانه بوده است؟ به وب نگاه کنید، شما نیز ممکن است چنین فکر کنید. به صورت جسته و گریخته فعالیت های شما اساسا توسط رهن کردن- اندوختن سرمایه و از دست دادن وزن تبلیغات کاملا ناخالص شده بود، هیچ یک از این موارد وارد حیطه های مربوط به ترسیم کردن هنر بزرگ اداره کننده ها نشدند. مربی رقص آن ها (اجرا کننده امور) و تعهد انجام شده توسط او فراتر از الگوریتم هایی می باشد که هر چیزی را به سوی دیوار (مانع) پرتاب می کند تا بتواند اتصال مربوط به آن را ببینند.
آیا با بهینه کردن تکنولوژی مربوط به تبلیغات و جایگذاری مربوط به محصول فیلتر شده و آماده رقابت، جستجو براساس خدمات تبلیغاتی، زمان واقعی مربوط به مناقضات خرید و موقعیت براساس مشخصه ها برای ابزارهای موبایل – همه این موارد مشتاقانه توسط بازاریابان ROI مورد توجه قرار می گیرد- ممکن است بتوان به آسانی در این زمینه نتیجه گیری کرد که تبلیغات فراتر از همه علوم می باشد و فاقد هنر است. اما سپس در راستای خلاقیت به روز و تازه به ما معاملات و فروش های حقیقی را نشان می دهد.
در صفحات بعدی ما به شش مورد از رقابت های برجسته توجه کردیم زیرا هر یک از آن ها در ذاتشان دارای ایده ای زیرکانه هستند یعنی یک جزئی که جدید می باشد و به صورت به روز تبلیغ می کند. به صورت همراه، آن ها تضمینی را فراهم می سازند که در راستای فعالیت های شرکت ها معامله انجام می دهند، در این صورت مشتریان نیاز به ترغیب شدن دارند – و خلاقیت مربوط به تبلیغات هرگز متوقف نمی شود.
قیمت: 3,000 تومان
ترجمه مقاله یک روش کنترل بردار ورودی و جایگزینی گیت ترکیب شده، برای کاهش جریان نشتی
دسته: برق
حجم فایل: 928 کیلوبایت
تعداد صفحه: 31
یک روش کنترل بردار ورودی و جایگزینی گیت ترکیب شده، برای کاهش جریان نشتی
چکیده__ کنترل بردار ورودی (IVC) تکنیک معروفی برای کاهش توان نشتی است. این روش، از اثر پشته های ترانزیستوری در دروازه های منطقی (گیت) CMOS _با اعمال مینیمم بردار نشتی (MLV) به ورودی های اولیه ی مدارات ترکیبی، در طی حالت آماده بکار_ استفاده می کند. اگرچه، روش IVC (کنترل بردار ورودی) ، برای مدارات با عمق منطقی زیاد کم تاثیر است، زیرا بردار ورودی در ورودی های اولیه تاثیر کمی بر روی نشتی گیت های درونی در سطح های منطقی بالا دارد. ما در این مقاله یک تکنیک برای غلبه بر این محدودیت ارایه می کنیم؛ بدین سان که گیت های درونی با بدترین حالت نشتی شان را، با دیگر گیت های کتابخانه جایگزین می کنیم، تا عملکرد صحیح مدار را در طی حالت فعال تثبیت کنیم. این اصلاح مدار، نیاز به تغیر مراحل طراحی نداشته، ولی دری را به سوی کاهش بیشتر نشتی _وقتی که روش MLV (مینیمم بردار نشتی) موثر نیست_ باز می کند. آنگاه ما، یک روش تقسیم-و-غلبه که جایگزینی گیت های را مجتمع می کند، یک الگوریتم جستجوی بهینه MLV برای مدارات درختی، و یک الگوریتم ژنتیک برای اتصال به مدارات درختی، را ارایه می کنیم. نتایج آزمایشی ما بر روی همه ی مدارات محک MCNC91، نشان می دهد که 1) روش جایگزینی گیت، به تنهایی می تواند 10% کاهش جریان نشتی را با روش های معروف، بدون هیچ افزایش تاخیر و کمی افزایش سطح، بدست آورد: 2) روش تقیسم-و-غلبه، نسبت به بهترین روش خالص IVC 24% و نسبت به روش جایگذاری نقطه کنترل موجود 12% بهتر است: 3) در مقایسه با نشتی بدست آمده از روش MLV بهینه در مدارات کوچک، روش ابتکاری جایگزینی گیت و روش تقسیم-و-غلبه، به ترتیب می توانند بطور متوسط 13% و 17% این نشتی را کاهش دهند.
قیمت: 12,000 تومان
سیستم استنتاج فازی تطبیقی برای پیش بینی سیستم های غیرخطی
- عنوان لاتین مقاله: Sequential Adaptive Fuzzy Inference System (SAFIS) for nonlinear system identification and prediction
- عنوان فارسی مقاله: سیستم استنتاج فازی تطبیقی (SAFIS) برای پیش بینی و شناسایی سیستم های غیرخطی
- دسته: برق و الکترونیک
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 24
- لینک دریافت رایگان نسخه انگلیسی مقاله: دانلود
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
در این مقاله سیستم استنتاج فازی تطبیقی به نام SAFIS، بر مبنای شباهت های عملکردی بین شبکه توابع بر پایه شعاع و سیستم استنتاج فازی (FIS) ایجاد می گردد. در سیستم SAFIS (استنتاج فازی تطبیقی) ، مفاهیم مربوط به تاثیر قوانین فازی معرفی شده و با استفاده از این موارد، قوانین فازی بر مبنای داده های اولیه ای که تا به حال دریافت شده اند، حذف یا اضافه می گردند. اگر داده های اولیه مانع اضافه شدن قوانین فازی شوند، به این ترتیب تنها پارامترهای مربوط به قوانین مشخص (در مفهوم اقلیدسی) با استفاده از طرح فیلتر کالمن به روز می گردند. عملکرد SAFIS (استنتاج فازی تطبیقی) با چندین الگوریتم موجود در ارتباط با مسئله ارزیابی مقایسه ای شناسایی دو سیستم غیر خطی و مسئله پیش بینی سری زمانی زمان پرهرج و مرج، مقایسه می گردد. نتایچ نشان می دهد که SAFIS (استنتاج فازی تطبیقی) در مقایسه با الگوهای دیگر با توجه به تعداد قوانین کمتر، صحت مشابه یا بهتری را ایجاد می کند.
کلمات کلیدی: سیستم استنتاج فازی تطبیقی زنجیره ای (SAFIS) ؛ GAP-RBF؛ GGAP-RBF؛ تاثیر قوانین فازی؛ فبلتر توسعه یافته کالمن.
مشخص است که سیستم استنتاج فازی (FIS) تقریبا مشابه طرح های ورودی و خروجی با در نظر گرفتن بعضی از قوانین مورد استفاده قرار می گیرد. در طرح FIS، دو فعالیت اصلی وجود دارد که شامل تعیین ساختار و انطباق پارامترها می باشد. شناسایی ساختارها به تعیین ورودی ها و خروجی ها، متغیرهای پیش رو و قبلی با توجه به قوانین مورد نظر، تعداد قوانین، و موقعیت تابع عضویت می پردازد. فعالیت ثانویه انطباق پارامتر شامل تشخیص پارامترها می باشد زیرا ساختار سیستم فازی در مراحل پیشین مشخص شده اند.
اخیرا، شباهت توابع بین َبکه های به هم پیوسته RBF، و FIS برای به اجرا در آوردن دو مرحله بالا مورد استفاده قرار گرفته است. این طرح از قابلیت های RBF برای تغییر قوانین و همچنین تنظیم پارامترها با توجه به اینکه سلول های پنهانی شبکه RBF در ارتباط با سیستم فازی می باشند، استفاده می کند.
- فرمت: zip
- حجم: 1.19 مگابایت
- شماره ثبت: 411
ترجمه مقاله یک مدل داده کاوی برای حفاظت خط انتقال مبتنی بر ادوات FACTS
 دسته: برق
دسته: برق حجم فایل: 1451 کیلوبایت
تعداد صفحه: 12
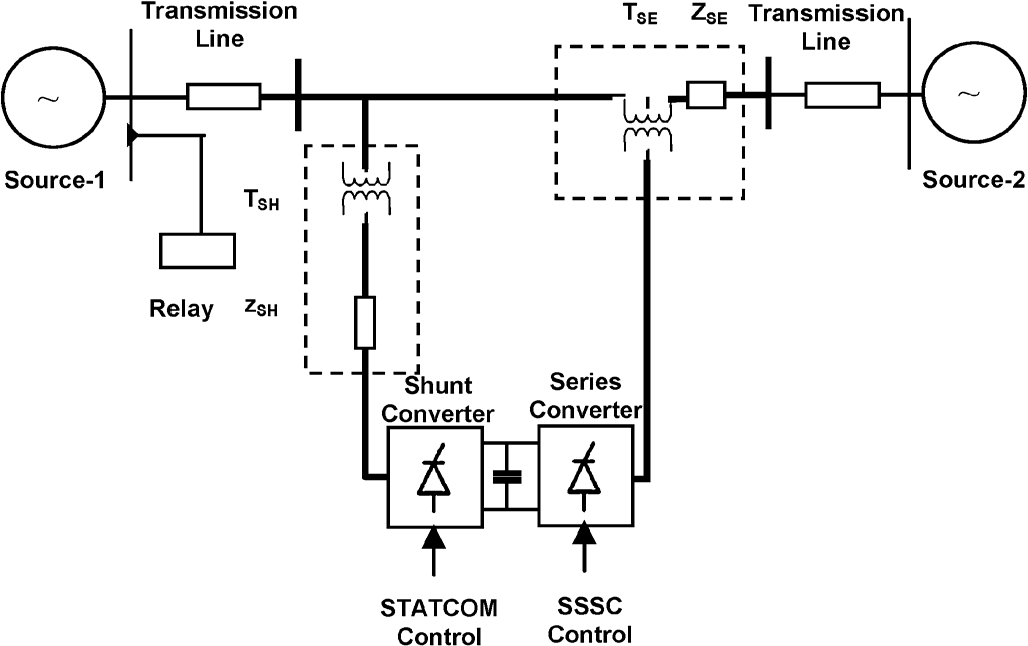
یک مدل دادهکاوی برای حفاظت خط انتقال مبتنی بر ادوات FACTS+ نسخه انگلیسی
A Data-Mining Model for Protection of FACTS-Based Transmission Line
چکیده- این مقاله یک مدل دادهکاوی برای شناسائی ناحیه خطای یک خط انتقال مبتنی بر سیستمهای انتقال ac انعطافپذیر (FACTS) ارائه میکند که شامل جبرانساز سری کنترلشده با تریستور (TCSC) و کنترلر یکپارچه عبور توان (UPFC) است، و از مجموعه درختان تصمیم استفاده میکند. با تصادفی بودن مجموعه درختان تصمیم در مدل جنگلهای تصادفی، تصمیم موثر برای شناسائی ناحیه خطا حاصل میشود. نمونههای جریان و ولتاژ نیم سیکل پس از لحظه وقوع خطا به عنوان بردار ورودی در برابر خروجی هدف "1" برای خطای پس از TCSC/UPFC و "1-" برای خطای قبل از TCSC/UPFC، برای شناسائی ناحیه خطا به کار میرود. این الگوریتم روی دادههای خطای شبیهسازی شده با تغییرات وسیع در پارامترهای عملکردی شبکه قدرت منجمله شرایط نویزی تست شده است و معیار قابلیت اطمینان 99% با پاسخ زمانی سریع بدست آمده است (سه چهارم سیکل پس از لحظه خطا). نتایج روش ارائه شده به کمک مدل جنگلهای تصادفی نشان دهنده تخیص قابل اعتماد ناحیه خطا در خطوط انتقال مبنی بر FACTS است.
عبارات کلیدی- رله دیستانس، تشخیص ناحیه خطا، جنگلهای تصادفی (RF ها) ، ماشین بردار پایه (SVM) ، جبرانسازی سری کنترلشده با تریستور (TCSC) ، کنترلر یکپارچه عبور توان (UPFC).
قیمت: 15,000 تومان
تابع هدف جدید محدب برای آموزش نظارت شبکه های عصبی تک لایه
- عنوان لاتین مقاله: A new convex obgective function for the supervised Learning of single-layer neural networks
- عنوان فارسی مقاله: تابع هدف جدید محدب برای آموزش نظارت شبکه های عصبی تک لایه .
- دسته: فناوری اطلاعات و کامپیوتر
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 28
- جهت دانلود رایگان نسخه انگلیسی این مقاله اینجا کلیک نمایید
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
چکیده: در این مقاله روش آموزش نظارت جدید برای ارزیابی چگونگی شبکه های Feed Forward عصبی تک لایه ارائه می شود. این روش از تابع هدفی بر مبنایMSE استفاده می کند، که خطاها را به جای این که پس از تابع فعالسازی غیرخطی نورون ها ارزیابی کند قبل از آن ها بررسی می کند. در این گونه موارد، راه حل را می توان به سهولت از طریق حل معادلات در سیستم های خطی به دست آورد یعنی در این روش نسبت به روش های معین و مرسوم پیشین به محاسبات کمتری نیاز است. تحقیقات تئوری شامل اثبات موازنه های تقریبی بین بهینه ستزی سراسری تابع هدف بر مبنای معیارMSE و یک تابع پیشنهادی دیگر می باشد. بعلاوه مشخص شده است که این روش قابلیت توسعه و توزیع آموزش را دارا می باشد. طی تحقیقات تجربی جامع نیز تنوع صحت در انرمان این روش مشخص شده است. این تحقیق شامل 10 دسته بندی و 16 مسئلۀ بازگشتی می باشد. بعلاوه، مقایسه این روش با دیگر الگوریتم های آموزشی با عملکرد بالا نشان می دهد که روش مذکور بطور متوسط بیشترین قابلیت اجرایی را داشته و به حداقل محاسبات در این روش نیاز می باشد.
1.« مقدمه »:
برای بررسی شبکه عصبیFeed Forward تک لایه با تابع فعالسازی خطی، مقادیر وزن برای تابع بهMSE حداقل رسیده و می توان این مقادیر را به وسیله یک ماتریس شبه معکوس بدست آورد [1,2]. بعلاوه، می توان اثبات کرد که سطح MSE این شبکه خطی تابعی درجه دوم می باشد [3]. بنابراین این سطحمحدب هایپر پارابولیک (فراسهمی وار) را می توان به سادگی با روش گرادیان نزولی (Gradient descent) طی کرد. با این حال، اگر ازتابع فعالسازی غیر خطی استفاده شود، مینیمم های محلی می توانند بر مبنای معیارMSE در تابع هدف دیده شوند [4-6]. طی تحقیقات مختلف می توان مشاهده نمود که تعداد چنین مینیمم هایی می توانند با ابعاد ورودی به صورت نمایی توسعه پیدا کند. تنها در برخی موارد خاص می توان تضمین کرد که شرایط حاکم، فاقدMin های محلی هستند. در مورد الگوهای تفکیک پذیرخطی و معیار آستانه MSE، وجود حداقل یک مقدارMin در تابع هدف به اثبات رسیده است [8,9]. با این حال، این امر یک موقعیت عمومی نمی باشد.
- فرمت: zip
- حجم: 1.30 مگابایت
- شماره ثبت: 411
رمزنگاری - 2
Cryptography with DNA binary strands - ScienceDirect.com …
Abstract. Biotechnological methods can be used for cryptography. Here two different cryptographic approaches based on DNA binary strands are shown. […] — ادامه متنCryptography - SSCP Study Guide and DVD Training …
This chapter deals with Systems Security Certified Practitioner exam cryptography. The cryptography area addresses the principles, means, and methods used to di […] — ادامه متنComputer Science - Springer
Computer Science The Hardware, Software and Heart of It. Computer Security and Public Key Cryptography. Wayne Raskind, Edward K. Blum. Look Inside Get Access. […] — ادامه متنرمزنگاری به همه روش ها (بخش 3)
دسته: امنیت | حجم فایل: 5600 کیلوبایت | تعداد صفحه: 1 | یکی از بهترین نرم افزارها در زمینه رمزنگاری (بخش 3) این نرم افزار بدلیل حجم بالا (34 مگابایت) در 3 بخش آپلود شده است. | بعد از دانلود هر 3 بخش، فایلها را از حالت فشرده خارج کرده و نصب کنید. مطمئن باشید از این نرم افزار کاملا لذت خواهید برد. […] — ادامه متنپروتکل مسیریابی در شبکه حسگر بی سیم
مقدمه | افزودن به ضریب عملکرد هکرها | سطح امنیت پیرامون | استاندارد شبکه های محلی بی سیم | شبکه های بی سیم و انواع آن | مقدار بر شبکه خصوصی مجازی | دسته بندی Vpn بر اساس رمزنگاری | دسته بندی Vpn بر اساس لایه پیاده سازی | مقایسه تشخیص نفوذ و پیشگیری از نفوذ | تفاوت شکلی تشخیص با پیشگیری | تشخیص نفوذ نتیجۀ نهایی | مقدمه ای بر تشخیص نفوذ | انواع حملات شبکه ای با توجه به طریقه حمله | انواع حملات شبکه ای با توجه به حمله کننده | پردازه تشخیص نفوذ | مقدمه ای بر Ipsec | انواع Ipsec Vpn | کاربرد پراکسی در امنیت شبکه | برخی از انواع پراکسی | Smtp Proxy | امنیت و پرتال | امنیت و پرتال Cms Pars | راهکارها […] — ادامه متنCryptography and Coding - Springer
Cryptography and Coding 12th IMA International Conference, Cryptography and Coding 2009, Cirencester, UK, December 15-17, 2009. Proceedings […] — ادامه متنUse of Elliptic Curves in Cryptography - Springer
We discuss the use of elliptic curves in cryptography. Odlyzko, A. M., Discrete logarithms in finite fields and their cryptographic significance, preprint. […] — ادامه متنPublic-Key Cryptography - Springer
Public-key cryptography ensures both secrecy and authenticity of communication using public-key encryption schemes and digital signatures, respectively. […] — ادامه متنرمزنگاری به همه روش ها (بخش 2)
دسته: امنیت | حجم فایل: 14336 کیلوبایت | تعداد صفحه: 1 | یکی از بهترین نرم افزارها در زمینه رمزنگاری (بخش 2) این نرم افزار بدلیل حجم بالا (34 مگابایت) در 3 بخش آپلود شده است. | بعد از دانلود هر 3 بخش، فایلها را از حالت فشرده خارج کرده و نصب کنید. مطمئن باشید از این نرم افزار کاملا لذت خواهید برد. […] — ادامه متنCryptography - Springer
Basic notions. Cryptography is the study of methods of sending messages in disguised form so that only the intended recipients can remove the disguise and read the […] — ادامه متنCryptography
Chapter 8 Cryptography 164 Encryption and decryption are done using a “key” or “code.” Sometimes, only one key is used to perform both […] — ادامه متنپاورپوینت
بخشی از فایل: | در فصل قبل در مورد امنیت و پروتکل های لایه های زیرین بحث شده است. | برای کاربردهای تجاری امنیت لایه های زیرین کافی نیست بلکه حداقل به امنیت در لایه انتقال نیاز داریم. | شرکت نت اسکیپ با طراحی یک بسته امنیتی Ssl یک لایه امنیتی بر روی لایه انتقال ایجاد کرد. هرگاه برنامه های کاربردی نیاز به اتصال امن داشته باشند از طریق Sslایجاد سوکت می کند. تا بتوانند از مزایای احراز هویت، فشرده سازی، رمزنگاری، بررسی صحت و اصالت داده، مذاکره مقدماتی روی پارامترها و الگوریتم های امنیتی استفاده کنند. | Sslعملیات خود را در دو مرحله انجام می دهد: | ۱-فرایند دست تکانی | ۲-مرحله تبادل داده […] — ادامه متنپاورپوینت امنیت شبکه
بیان مساله | حملات، سرویس ها و مکانیزم ها | سرویس امنیتی | حملات امنیتی | انواع کلی حملات | توزیع ویروس Code Red | مکانیزم امنیتی | رمزنگاری | انواع روشهای رمزنگاری | انواع روشهای رمزنگاری مبتنی بر کلید […] — ادامه متنDisappearing Cryptography - (Third Edition) - ScienceDirect
The online version of Disappearing Cryptography by Peter Wayner on ScienceDirect.com, the world"s leading platform for high quality peer-reviewed full-text … […] — ادامه متنCryptography - Springer
Broadly speaking, the term cryptography refers to a wide range of security issues in the transmission and safeguarding of information. Most of the applications of […] — ادامه متنگزارش کارآموزی مخابرات
فهرست مطالب: | مقدمه ۱ | نمودار سازمانی ۲ | انواع انتقال ۳ | انواع مراکز ۴ | انواع سو ئیچینگ ۶ | سیگنالینگ ۶ | مراکز تلفن۷ | مکانیزم مخابرات ۱۰ | واحد سوئیچ ۱۱ | کارتهای موجود در سوئیچ ۱۱ | چک سوئیچ۱۲ | راه اندازی یک مرکز۱۳ | شبکه های خصوصی مجازی (Vpn | دسته بندی Vpn بر اساس رمزنگاری ۱۷ | دسته بندی Vpn بر اساس لایه پیاده سازی ۱۷ | دسته بندی Vpn بر اساس کارکرد تجاری۱۹ | مختصری درباره تئوری Vpn | پیاده سازی Vpn | پرتکل های مورد استفاده۲۱ […] — ادامه متنError-correcting codes and cryptography - Springer
In this paper, we give and explain some illustrative examples of research topics where error-correcting codes overlap with cryptography. In some of these examples […] — ادامه متناستراتژی برای استتار فعال جنبش
چکیده
در این مقاله ما این موضوع را در نظر می گیریم که آیا یک حیوان و یا یک ایجنت (یک’ shadower’) قادر است تا بصورت فعال حرکات خود را مستتر کند در عین حال که حیوان و یا ایجنت دیگری را تعقیب می کند. نشان داده می شود که تحت یک شرایط خاص، تعقیب کننده چنانچه در یک مسیر به گونه ای حرکت کند که نور تولیدشده توسط یک شی ساکن از منظر شی تحت تعقیب را تقلید کند، می تواند حرکت خود را مخفی کند. برای تعیین مسیرهایی که shadower را قادر سازد تا حین تعقیب shadower، یا حین حرکت به سمت یک هدف ساکن یا متحرک، بتواند حرکت خود را مستتر کند، الگوریتم هایی توسعه یافته و تست شدند. استراتژی های ارائه شده بدون توجه به اینکه shadower در یک پس زمینه ساختاریافته و یا همگن در نظر گرفته شود، کار می کنند. بررسی موضوع استتار فعال جنبشی در مفاهیمی چون رفتار «تعقیب کنندگی» در زنبورها، دستگیری طعمه توسط شکارچیان و مانورهای نظامی قابل توجه و مورد علاقه است.
مقدمه
وقتی یک حیوان و یا یک روبات حرکت می کند، تصاویر اشیاء پیرامون روی شبکیه چشم (یا روی سطح تصویربرداری دوربین روبات) حرکت می کنند، حتی اگر این اشیا از لحاظ فیزیکی بصورت ساکن باشند. با این حال، برخی حیوانات من جمله حشرات وقتی درحال حرکت باشند قادر به تشخیص اشیاء ساکن و متحرک هستند. معمولا، جریان نور تابیده شده از یک شی متحرک با نور حاصل از اشیاء ساکن متفاوت است. بطور واضح، سیستم های بصری بیشتر حیوانات قادر به تشخیص این تفاوت هستند، اما این موضوع جای سوال دارد: چگونه یک حیوان (یا ایجنت) می تواند بدون دور کردن خود با حرکت خویش، دیگری را تعقیب یا ‘shadow’ کند؟
داده کاوی جهانی: مطالعه تجربی از روند فعلی پیش بینی آینده و انتشار فناوری
- عنوان لاتین مقاله: Global data mining: An empirical study of current trends, future forecasts and technology diffusions
- عنوان فارسی مقاله: داده کاوی جهانی: مطالعه تجربی از روند فعلی پیش بینی آینده و انتشار فناوری
- دسته: فناوری اطلاعات و کامپیوتر
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 28
- جهت دانلود رایگان نسخه انگلیسی این مقاله اینجا کلیک نمایید
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
با استفاده از روش داده کاوی این مطالعه و تجلیل روند تحقیقات و پیش بینی داده کاوی را از سال 1989 تا سال 2009 را با عنوان داده کاوی در پایگاه SSCI انجام داده است روش کتاب سنجی تحلیل روشی بررسی موضوع در این بازه زمانی است. ما با برداشت از 1881 مقاله به بررسی این موضوع پرداخته ایم در این مقاله پیاده سازی و طبقه بندی مقالات داده کاوی با استفاده از سال نشر، استناد، کشور نشر، نوع سند، نام موسسه، زبان، عنوان منبع و موضوع منطقه برای وضعیت های مختلف به منظور کشف تفاوت ها و اطلاعات چگونگی فناوری و توسعه یافتگی آن در این دوره با گرایش های فناوری پرداخته ایم و پیش بینی نتایج را از این مقالات انجام داده ایم همچنین این مقاله انجام آزمون K-S را برای بررسی اینکه آیا تجزیه و تحلیل براساس قانون لوکتا است یا نه انجام دادند. علاوه براین تجزیه و تحلیل بررسی متون تاریخی جهت نفوذ فناوری داده کاوی انجام شده است. این مقاله یک نقشه راه برای تحقیقات آینده، و روندهای تکنولوژی و پیش بینی و تسهیل انباشت دانش را در دستور خود دارد به طوری که محققان داده کاوی بتواند با صرف هزینه کم بر روی موضوع مشخص خود متمرکز شوند.
این بدان معنی است که پدیده موفقیت در نشریات با کیفیت بالاتر شایع تر است
کلیده واژه ها: داده کاوی، روند تحقیقات و پیش بینی، نفوذ فناوری و روش کتاب سنجی
مقدمه
داده کاوی زمینه بین رشته ای است که ترکیبی مصنوعی از هوش، مدیریت پایگاه داده، تجسم داده ها، دستگاه یادگیری، الگوریتم های ریاضی و آمار را به وجود آورده است. داده کاوی نیز به عنوان کشف پایگاه داده ها شناخته شده است. دچن، هان ویو 1996، پیاتتکسی و اسمیت 1996 که به سرعت در حال ظهور می باشند. این فناوریها روش های مختلفی را برای تصمیم گیری حل مسئاله، تجزیه و تحلیل، برنامه ریزی، تشخیص، یکپارچه سازی، پیشگیری آموزش و نوآوری را به ارمغان می آورد که نیاز به تکنیک های جدید برای کمک به تجزیه و تحلیل، درک و حتی تجسم مقدار بسیار عظیمی از داده های ذخیره شده را در برنامه های علمی و کاربردی را جمع آوری می کند. کشف دانش این فرآیند جالب توجه است.
- فرمت: zip
- حجم: 0.44 مگابایت
- شماره ثبت: 411